Building a car recognition application (pt. 1)
Implementing a car recognition app used to mean collecting images, labeling them, and training a model before you could ship anything. Now you point a phone at a car, send the photo to a multimodal LLM (Claude, Gemini, or GPT), and get back the results in an afternoon.

That speed is real, and so is the catch. Every scan is a billed API call, the price and the model are set by someone else, and when the provider has a bad day your app has one too. It is the cheapest way to start but an expensive way to grow.
This post builds such a prototype and instruments it, so you can see what the convenience actually costs. In the next parts we will train a specialized model with an effort to replace the remote one.
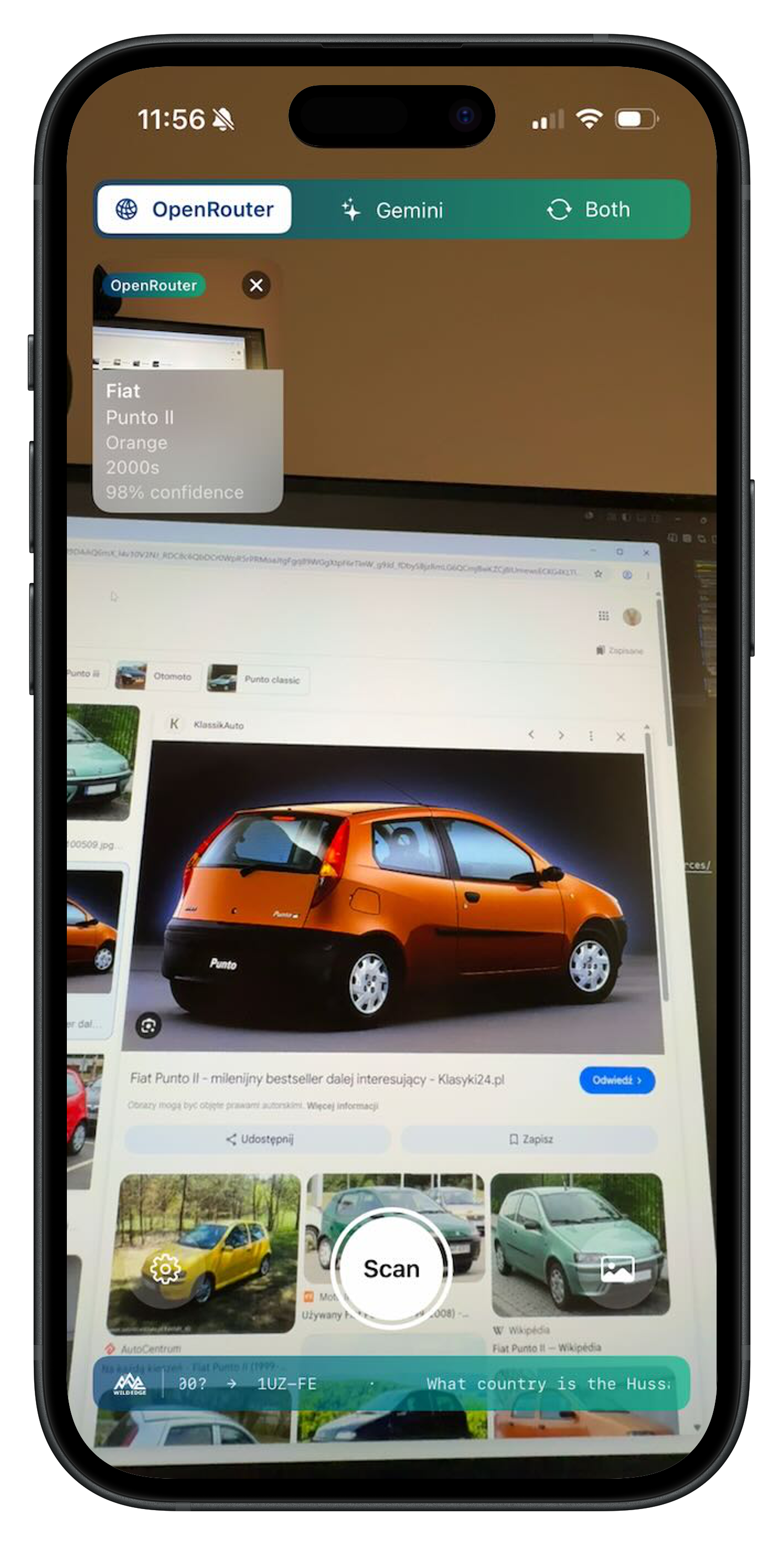
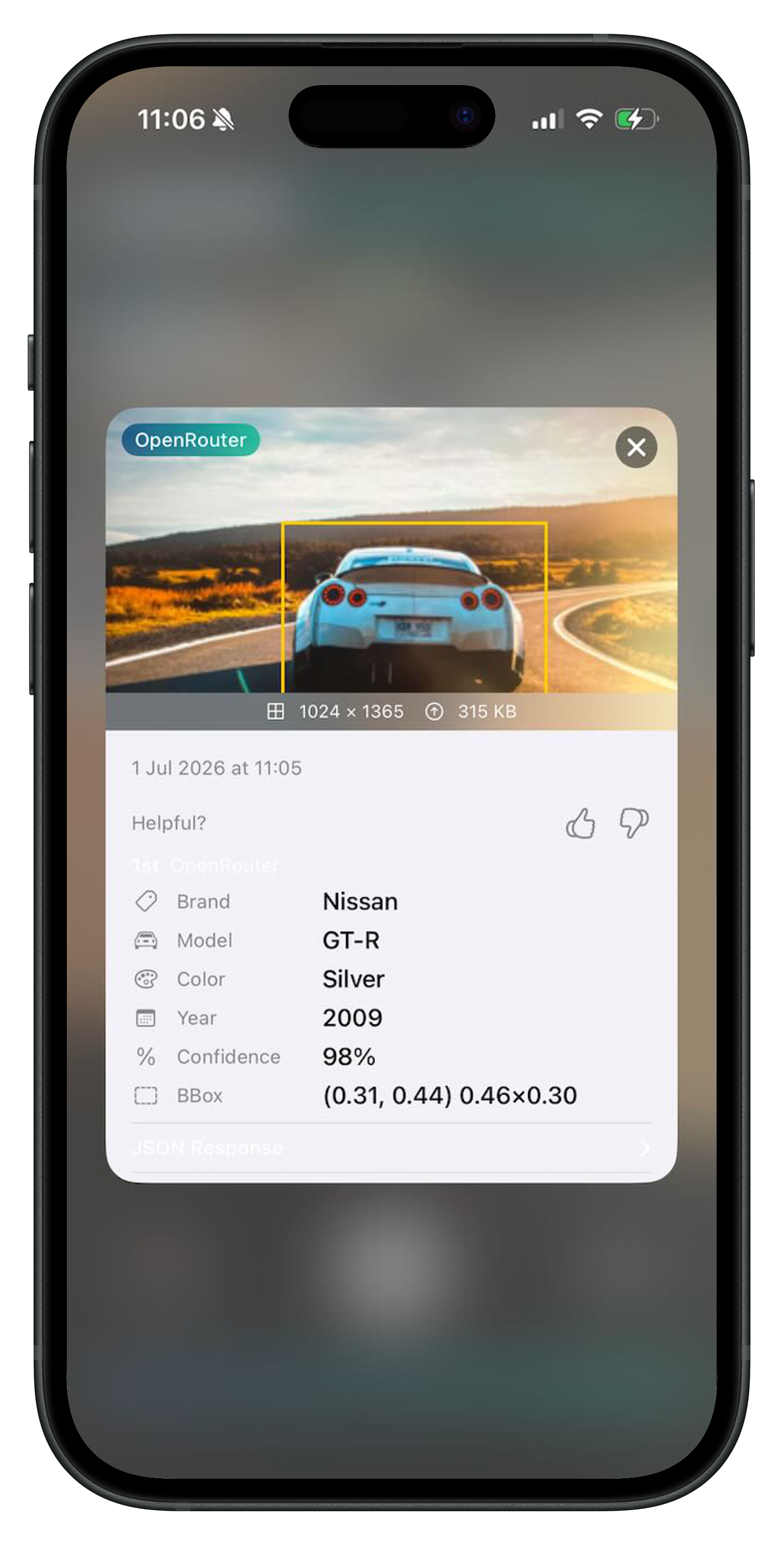
CarScanner is our open-source iOS experimentation app. Point it at a car and it returns: the make, model, color, approximate year, and a bounding box around the vehicle.
It calls Gemini directly or through OpenRouter, both currently pointing at Gemini 2.5 Flash. OpenRouter is there so you can later swap in any model it supports without touching the Swift code. The first version took an afternoon. Here is most of the interesting code (GeminiClient.swift):
func recognizeCar(image: UIImage) async throws -> CarRecognition {
let base64 = image.jpegData(compressionQuality: 0.8)!
.base64EncodedString()
let response = try await gemini.generateContent(
systemInstruction: carRecognitionPrompt,
parts: [.data(mimetype: "image/jpeg", base64)]
)
return try JSONDecoder().decode(
CarRecognition.self,
from: response.text!.data(using: .utf8)!
)
}Gemini owns the model, the training data, and the inference pipeline. Your side of it is a prompt and a decoder.
What the API returns
The structured response includes make, model, color, year_range, body_style, and a confidence score from 0 to 1.
{
"make": "Toyota",
"model": "Camry",
"color": "Silver",
"year_range": "2018-2021",
"body_style": "Sedan",
"confidence": 0.94
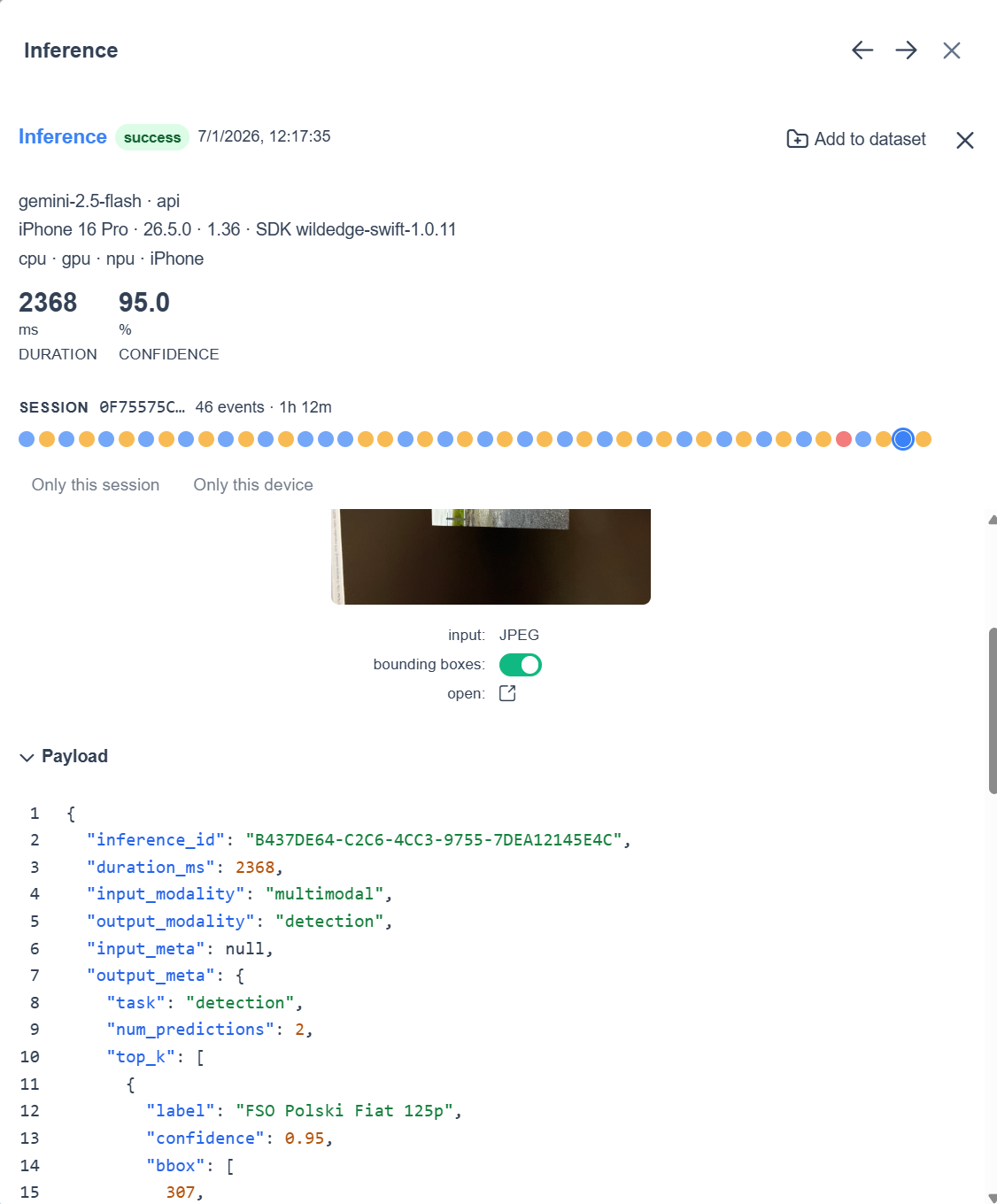
}Every call is captured as a WildEdge inference event, so here is a real one, payload and all:
One caveat on that last field: confidence here is not a calibrated probability. It is a number you asked the model to produce, so treat it as the model's opinion of itself, not a measurement.
For a prototype, that is plenty. The generalist copes with partial occlusion, bad lighting, odd angles, and models it was never specifically tuned for. You get broad coverage for free.
What the numbers look like after an afternoon of scanning
Before writing another line of product code, we instrumented the API calls with WildEdge. Every call becomes one inference event, carrying latency, confidence, cost, model version, and the full response (GeminiClient.swift):
import WildEdgeSDK
let gemini = WEGeminiClient(
apiKey: apiKey,
dsn: "https://...",
modelName: "gemini-2.5-flash"
)That swap is the whole instrumentation step. Every chart in this section is rendered straight from the resulting inference events in the WildEdge dashboard, not plotted by hand.
After a couple dozen scans in a parking lot (23 inferences in one afternoon session), the WildEdge dashboard gave us our first real read on what the prototype actually does: 2.6s average latency, a 3.5s p95, a 0% error rate, and confidence that barely moves.
Latency
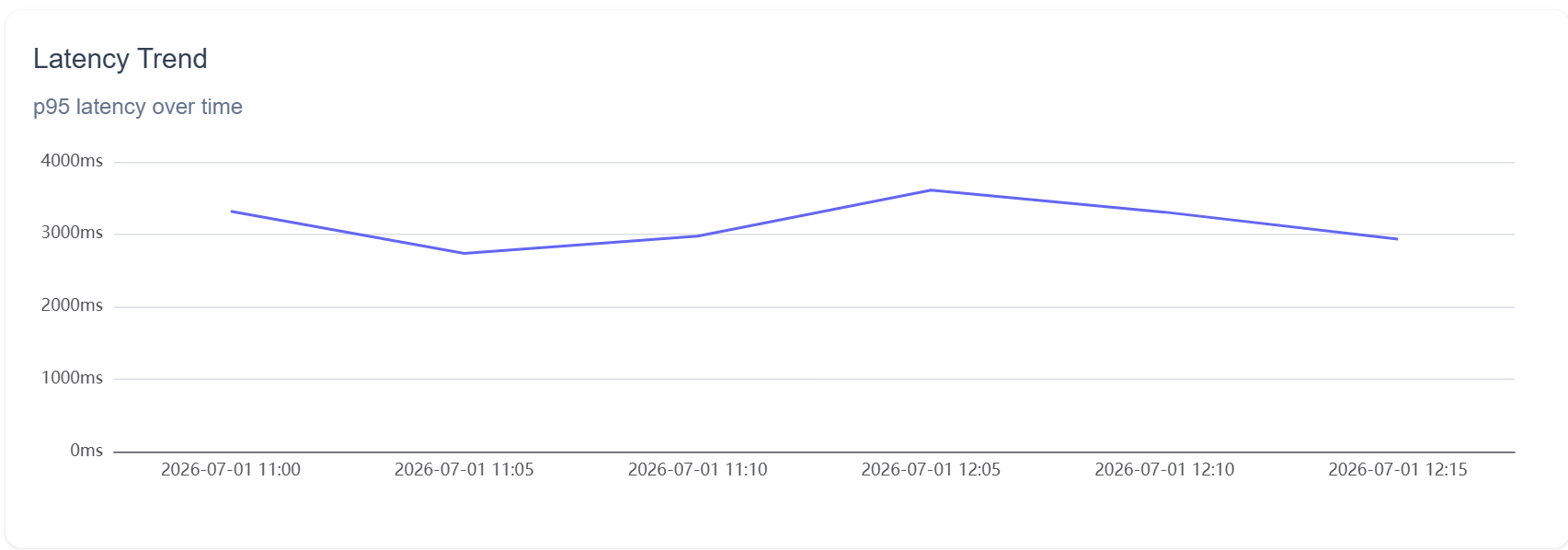
Average round-trip was 2.6 seconds, and p95 was 3.5 seconds, with the p95 trend wandering between 2.7 and 3.6 seconds across the session. For an app where you point your phone and expect an instant answer, 2.6 seconds already feels slow, and a 3.5-second tail is long enough that you start to wonder whether it crashed. A representative single scan took 2,368 ms end to end.
These numbers are effectively a floor, measured under gigabit Wi-Fi with full signal. On a congested cell network, in a parking garage, or anywhere with a weak signal, real-world latency only goes up from here.
Confidence
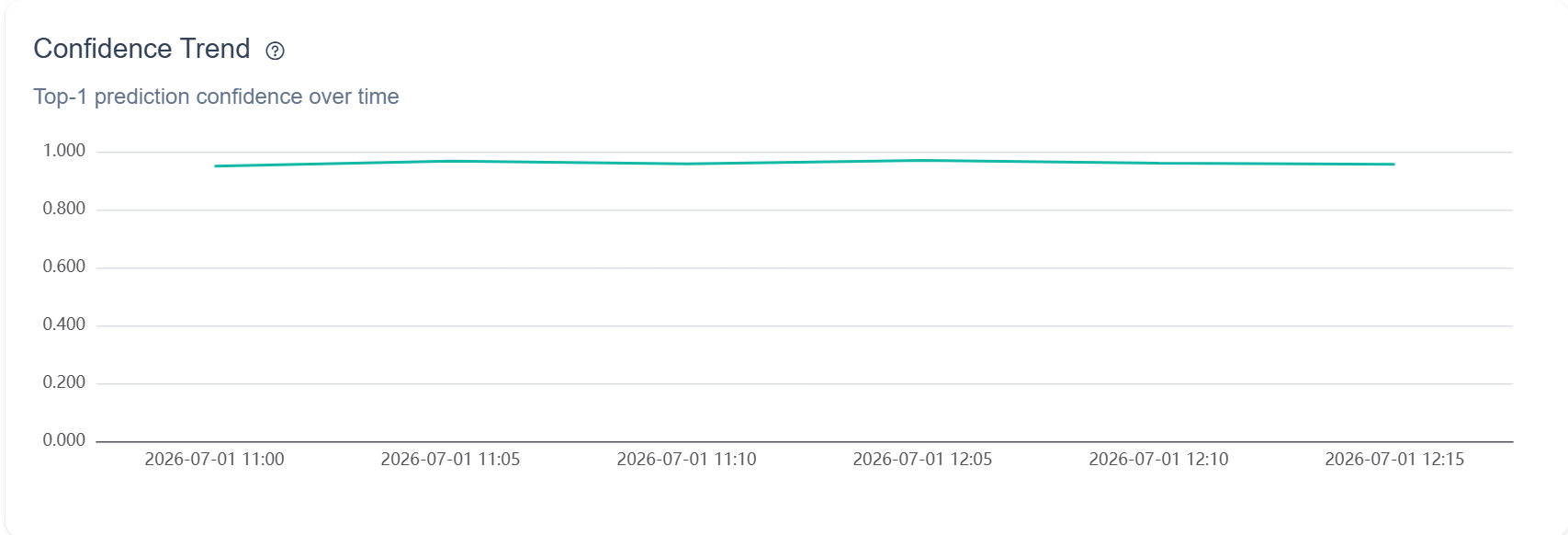
Self-reported confidence sat around 0.95 and barely moved. The top-1 trend held between 0.95 and 0.97 across the whole session, and WildEdge's confidence-drift index (PSI) came back at 0.0000, no drift at all. That flatness is the story. The model returns a high number on almost everything, including the harder cases (partial cars, odd angles, models it was never tuned for), which is exactly why the confidence field is the model's opinion of itself rather than a measurement. A verdict from the person holding the phone is worth more than any of these numbers.
Coverage
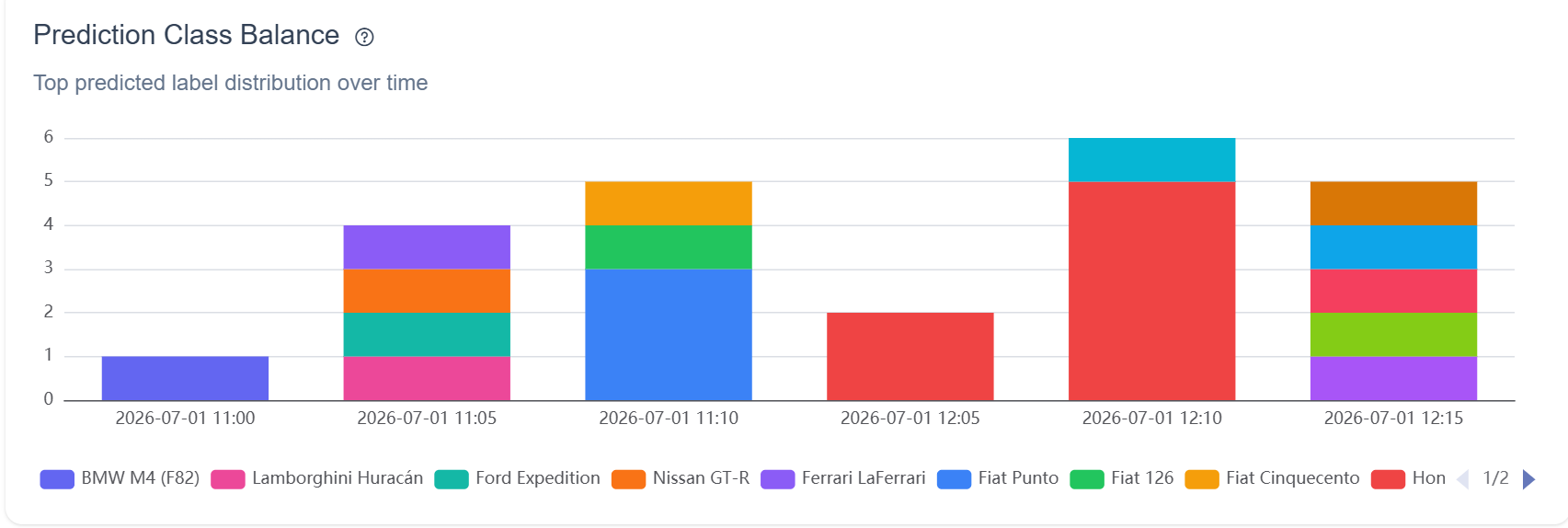
The generalist recognized a genuinely mixed bag with no tuning: a BMW M4, a Lamborghini Huracán, a Ford Expedition, a Nissan GT-R, a Ferrari LaFerrari, and a run of Fiats (Punto, 126, Cinquecento) all came back labeled in a single afternoon. That spread is the "broad coverage for free" that makes a generalist such a good first guess.
Cost
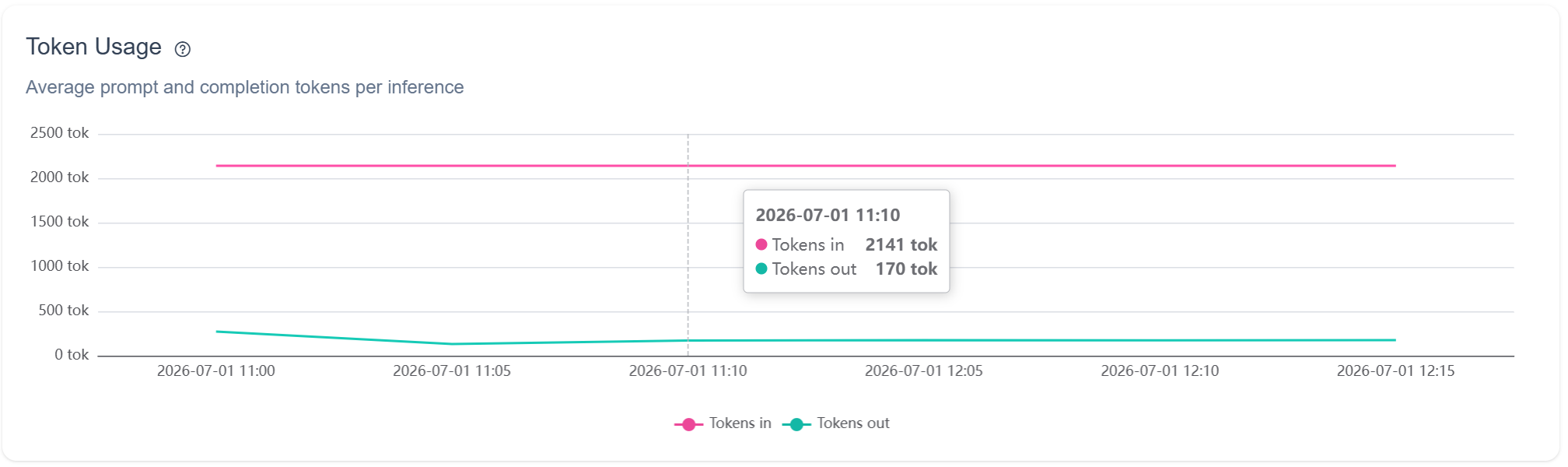
Every scan costs money, and the marginal cost never goes to zero. Each scan actually sent about 2,141 tokens in and got 170 back, with most of the input being the system prompt rather than the image.
At a thousand users it is a rounding error. The problem is what success does to that number.
| Model | $/1M (in · out) | Tokens (in · out) | $/scan | 1k users, 5 scans/mo | 1M users, 5 scans/mo |
|---|---|---|---|---|---|
| Gemini 2.5 Flash | $0.30 · $2.50 | 2,141 · 170 | ~$0.0011 | ~$5 | ~$5k/mo (~$64k/yr) |
| Claude Haiku 4.5 | $1.00 · $5.00 | ~3,500 · ~170 | ~$0.0044 | ~$22 | ~$22k/mo (~$261k/yr) |
| GPT-4o† | ~$2.50 · ~$10 | ~2,665 · ~170 | ~$0.0084 | ~$42 | ~$42k/mo (~$502k/yr) |
| Claude Sonnet 4.6 | $3.00 · $15.00 | ~3,500 · ~170 | ~$0.013 | ~$65 | ~$65k/mo (~$783k/yr) |
Only the Gemini row is measured. These are floor numbers: CarScanner makes one call per scan while real pipelines stack a detection pass, a verification step, a summary, a low-confidence retry. Multiply the table by however many passes your flow actually makes.
The other rows reuse Gemini's measured ~1,900-token text prompt and ~170-token JSON response, then add each model's own image tokenization (Gemini bills a small image at a flat ~258 tokens, while Claude and GPT-4o use tile-based schemes that land higher). Output is only 170 tokens but is priced several times higher than input, so it is a real slice of the per-scan cost, not a rounding error.
† GPT-4o pricing has changed multiple times. Verify at openai.com before relying on this figure.
Control
A real problem is the price (latency, uptime,..) is not yours to set. The vendor can change it, and the model you validated against can be deprecated out from under you on someone else's schedule. This forces a migration and a fresh round of validation whether you have time for it or not. Rate limits and terms move the same way, which is the reliability problem from a different angle. None of this is a prediction that prices will rise as historically API prices have mostly fallen. It is that you don't control your own unit economics or your own model. A self hosted or on-device model settles all of it at training time. The per-scan cost is zero and nobody can revise it.
Reliability
OpenAI, Anthropic, and Google all run status pages, and all three fill them with the same recurring entries: elevated error rates, degraded performance, outright outages. Anthropic logged ten disruptions in twelve days in June 2026 as its infrastructure strained under rapid growth. OpenAI has seen multi-component outages that took down login, APIs, and image generation at once. Switching providers does not remove the dependency, it just moves it. When the API is down, your app shows nothing. An on-device model has no status page because it has nothing to go down.
How the apps that shipped this solved it
The apps people actually rely on in the field recognize what they are pointed at without a round trip to a server.
Merlin from the Cornell Lab identifies bird species from photos and sound entirely on-device, trained on tens of millions of labeled observations contributed by the birdwatching community. Its users are standing in forests with no signal, so running offline isn't a feature for them, it's the whole point of the app.
Seek from iNaturalist does the same for plants and wildlife. Running on-device was partly a privacy decision: Seek is aimed at younger users, and routing their photos through a server is a much harder conversation to have with parents and schools.
Even Pl@ntNet, which runs its full model on its own servers, ships a compressed version that lives on the phone, so identification keeps working when there is no signal to reach those servers.
The pattern underneath all of them is the same. You assemble a labeled dataset, train a classifier, compress it for the device, and ship it.
Where this goes
Gemini migt not be the product, but it makes a decent first guess on every scan. The asset isn't the guess, it's the verdict the person holding the phone gives it, scan after scan.
Every scan becomes an inference event in WildEdge, carrying the model's answer, the confidence score, and the user's correction when there is one. CarScanner captures corrections through thumbs-up and thumbs-down buttons. Each tap links the rating back to the original inference and records how long after the scan the user responded (ScanJobDetailView.swift, CameraViewModel.swift):
private func makeFeedback(
_ handle: ModelHandle,
inferenceId: String,
inferenceDate: Date
) -> (FeedbackType) -> Void {
{ feedbackType in
let delayMs = Int(Date().timeIntervalSince(inferenceDate) * 1000)
handle.trackFeedback(
feedbackType,
relatedInferenceId: inferenceId,
delayMs: delayMs
)
}
}That signal is what drives sample selection. A high-confidence answer that turns out wrong flags a label that would quietly poison a training set. A low-confidence answer that turns out right points to the hard cases a specialist has to get right. API responses on their own tell you none of this. Pair them with feedback from real use and you have a dataset worth training on.
The open question is whether that signal is enough. A thumbs-up confirms a guess, but a thumbs-down only tells you the answer was wrong, not what the right one was, and users scan the common cars far more than the rare ones the generalist already struggles with. So the feedback piles up fastest exactly where you need it least. Whether coarse signal at real-world volume produces a balanced, trustworthy training set, especially in that tail, is the thing to actually measure rather than assume.
Our target for this series is an on-device classifier that costs nothing per scan, works offline, fits in on a relatively modern iOS device, and returns a result in under 100ms. Our assumption is that on a closed vocabulary it was trained for, a specialist will beat a generalist.
If the specialist is too big to run on the phone, the fallback is to host it on your own infrastructure. You still own the model and still escape per-token vendor pricing, but you give up the offline and zero-marginal-cost wins and take on the uptime yourself.
Satya Mallick of OpenCV ran a comparison on car detection and found purpose-built models like YOLO/RF-DETR answer in milliseconds where a general multimodal LLM "burns thousands of tokens" for worse accuracy. For structured output the suggestion was to leverage Qwen-3VL or Moondream 3 (VLM). This exactly the plan we aim to follow.
Our next post goes through this in detail: how user feedback turns raw scans into a labeled set, what the confidence distribution looks like across makes and models, and where that feedback parts ways with Gemini's own confidence. The samples worth training on tend to sit right in that gap.
Help build the dataset
The CarScanner TestFlight beta is open on iOS: email [email protected] for an invite. Every car you scan and every thumbs-up or thumbs-down feeds directly into the labeled set this series is built on.
Links
CarScanner is open source. The full prompt, the Swift client, and the WildEdge instrumentation are all there. It lives in the Examples/ directory of the wildedge-swift SDK alongside examples for TFLite, ONNX, Core ML, and llama.cpp.
Check us out!
Sign up at wildedge.dev and instrument your first model in minutes. The SDKs are open source: github.com/wild-edge.
Follow the series and the team on X (@getWildEdge), LinkedIn, and GitHub.